Seata currently supports multiple registry center implementations. To provide complete end-to-end functionality, Seata has designed and launched its native registry center called namingserver.
2. Domain Model
2.1 Namespace and Transaction Groups
- Namespace: In the NamingServer model, namespaces are used to achieve environment isolation. They allow service instances to be isolated across different environments (such as development, testing, and production).
- Cluster and Unit: Clusters handle transaction group processing, while Units perform load balancing within each cluster. Transaction groups (vgroups) locate specific TC nodes through metadata coordination between namespaces and clusters.
2.2 Transaction Processing Flow and NamingServer Interaction
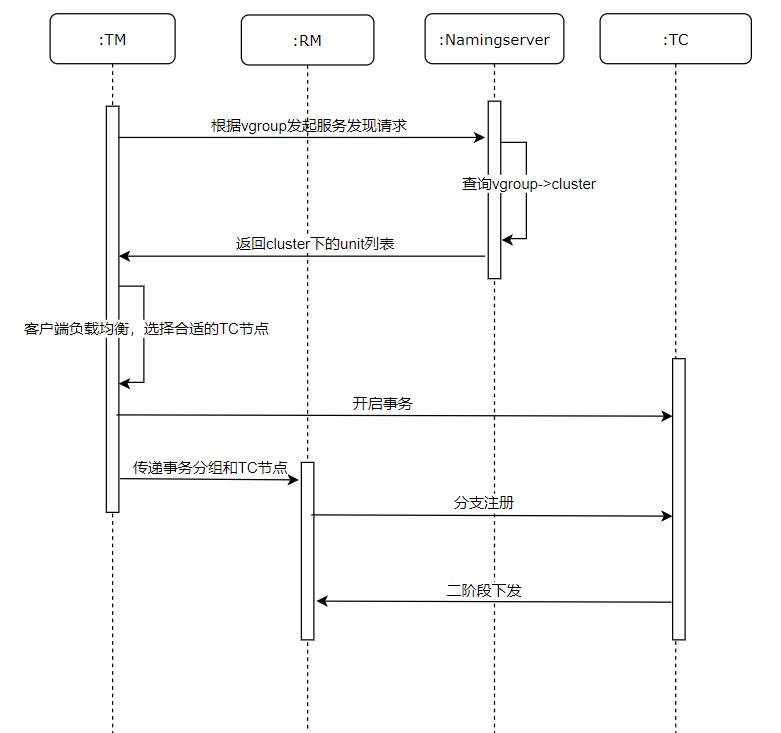 The interaction flow between transaction processing and namingserver is as follows:
The interaction flow between transaction processing and namingserver is as follows:
-
Configure the NamingServer address and related settings on the client side
-
After client startup, TM sends a service discovery request to namingserver
-
NamingServer returns the related cluster list based on the vGroup parameters sent by TM and the transaction group mapping relationships in memory. The cluster list metadata returned by namingserver is as follows:
{
"clusterList": [
{
"clusterName": "cluster2",
"clusterType": "default",
"groupList":[group1,group2]
"unitData": [
{
"unitName": "115482ee-cf27-45d6-b17e-31b9e2d7892f",
"namingInstanceList": [
{
"ip": "172.31.31.191",
"port": 8092,
"nettyPort": 0,
"grpcPort": 0,
"weight": 1.0,
"healthy": true,
"timeStamp": 1695042063334,
"role": member,
"metadata": {
"weight": 1,
"cluster-type": "default"
}
}
]
},
{
"unitName": "097e6ab7-d2d2-47e4-a578-fae1a4f4c517",
"namingInstanceList": [
{
"ip": "172.31.31.191",
"port": 8091,
"nettyPort": 0,
"grpcPort": 0,
"weight": 1.0,
"healthy": true,
"timeStamp": 1695042076481,
"role": member,
"metadata": {
"weight": 1,
"cluster-type": "default"
}
}
]
}
]
}
],
"term": 1695042076578
}
-
The client identifies the appropriate TC node through load balancing strategy to start transactions
-
TM passes the transaction group and TC node to RM
-
RM sends branch registration requests to the TC node
-
TC node completes the second-phase distribution
3. Design Philosophy
3.1 AP or CP?
The CAP theorem, also known as the CAP principle, states that in a distributed system, Consistency, Availability, and Partition tolerance cannot all be achieved simultaneously. The CAP theory for distributed systems categorizes these three characteristics as follows:
● Consistency (C): Whether all data backups in a distributed system have the same value at the same moment (equivalent to all nodes accessing the same latest data copy)
● Availability (A): Whether the cluster as a whole can still respond to client read and write requests after some nodes in the cluster fail (high availability for data updates)
● Partition tolerance (P): In practical terms, partitioning is equivalent to time limit requirements for communication. If the system cannot achieve data consistency within the time limit, it means partitioning has occurred, and a choice must be made between C and A for the current operation.
For namingserver, we prefer to use the AP model, emphasizing availability and partition tolerance while sacrificing some consistency. As a service registry center, NamingServer's primary responsibility is to provide efficient service discovery and registration services, while requirements for short-term data consistency can be appropriately relaxed. In distributed environments, there may be brief inconsistencies in registration data across multiple nodes. For example, when multiple NamingServer nodes experience network partitioning, some nodes may have delayed registration information.
For NamingServer, we consider this temporary inconsistency tolerable. Since service registration and discovery don't require strong consistency, even if some nodes have lagged or inconsistent registration data at a given moment, it won't immediately affect the normal service of the entire system. Through heartbeat mechanisms and periodic synchronization, eventual consistency can be gradually guaranteed.
3.2 Application of Quorum NWR Mechanism in NamingServer
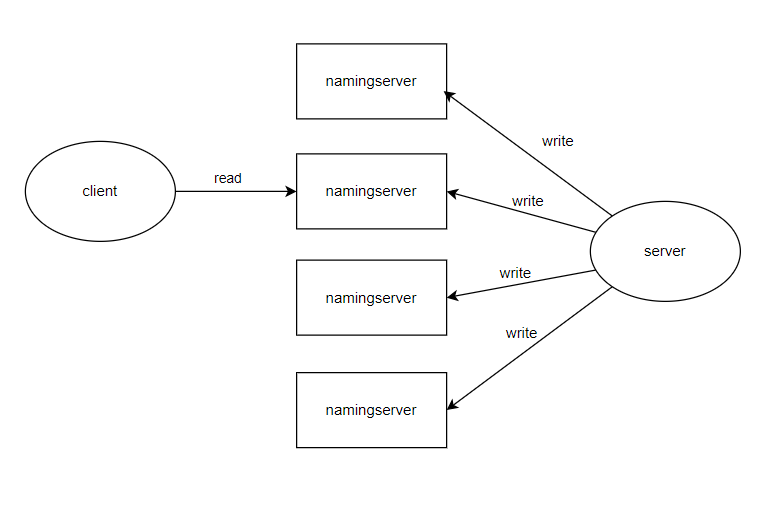
Quorum NWR (Quorum Read-Write) is a mechanism used in distributed systems to ensure data consistency. This mechanism coordinates data consistency by setting the total number of replicas (N), the number of replicas required for successful write operations (W), and the number of replicas to access for read operations (R). In NamingServer's design, a multi-write + compensation mechanism is adopted to ensure information consistency among multiple NamingServer nodes, while clients interact with a single NamingServer node to obtain registration information.
-
Write Operations (W-Write Quorum): When cluster node changes occur, the server side sends requests to multiple nodes in the NamingServer cluster. According to the NWR mechanism, the system ensures that at least W replicas successfully write registration information. Through the multi-write mechanism, even if some nodes are temporarily unavailable or experience network delays, write operation high availability can still be ensured. Once W nodes successfully write, the client receives a success response. Compensation Mechanism: For replicas that don't immediately succeed in writing, the system uses asynchronous compensation to synchronize these nodes at a later time, ensuring eventual consistency.
-
Read Operations (R-Read Quorum): Clients interact with any node in the NamingServer cluster, sending read requests to obtain service registration information. The system reads data from at least R replicas, using the latest version of data as the return result. Even if some nodes have temporarily inconsistent data, clients can ensure they read the latest registration information by reading multiple replicas and comparing their version numbers or consistency markers. Since clients only interact with one NamingServer node, read operation efficiency is improved, and complex coordination between multiple nodes is avoided while the system still ensures eventual consistency.
-
NWR Parameter Design and Trade-offs: In namingserver, we set W=N and R=1. While W=N means writes need to be sent to all nodes, it doesn't require all nodes to immediately succeed in writing. The system allows some nodes to temporarily fail, synchronizing these nodes through compensation mechanisms in subsequent stages, thereby improving system fault tolerance. Even if some nodes fail or experience network interruptions during writing, data updates can still eventually propagate to all nodes through compensation mechanisms. This ensures both high system availability and eventual data consistency across all nodes. Since write operations require all nodes to participate, each node receives the latest data updates. When clients perform read operations, they can read data from any NamingServer node without worrying about data inconsistency. Even if some nodes don't immediately succeed during writing, clients can still obtain the latest registration information from other successfully written nodes. Thus, the R value can be set relatively low (such as R=1) to improve read operation efficiency, while the system ensures all nodes eventually reach consistency through compensation mechanisms.
3.2 Architecture Diagram
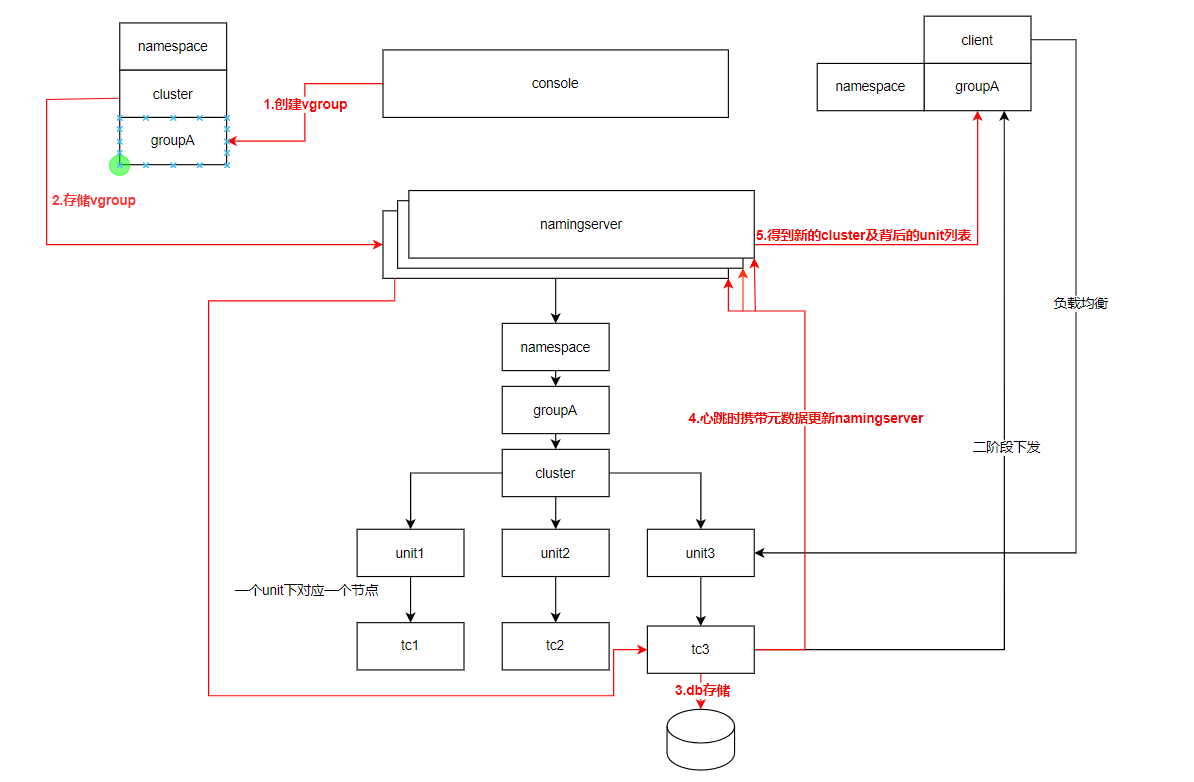
The namingserver operation flow is shown in the diagram above:
- Create a transaction group vgroup under a certain cluster through the console.
- The vgroup->cluster creation request is sent to namingserver, which then forwards it to the corresponding TC node.
- The TC node persistently saves the vgroup->cluster mapping relationship.
- During heartbeats, the TC node updates the vgroup->cluster mapping relationship to all namingservers.
- The client obtains corresponding cluster metadata from namingserver using its configured transaction group vgroup.
- During transaction flow, the client uses units under the cluster for load balancing, then performs begin, registry, commit, rollback operations.
- After transaction decision, the leader node under the corresponding unit distributes the second phase. In stateless nodes, the unique node under each unit is the leader.
3.3 Design Details
3.3.1 Long Polling for Cluster Change Notifications
As shown in the diagram above, every 30 seconds the client needs to send a service discovery request to namingserver to pull the latest TC list. During this 30-second interval, the client uses HTTP long polling to continuously watch the namingserver node. If the namingserver side has the following changes:
Changes in transaction group mapping relationships;
Addition or removal of instances in the cluster;
Changes in cluster instance properties;
Then the watch returns a 200 status code, informing the client to obtain the latest cluster information. Otherwise, namingserver will keep the watch method pending until the HTTP long polling times out, then return a 304 status code, telling the client to proceed with the next round of watching.